It is difficult to overestimate the importance of reading for learning any foreign language. Even more so with Chinese, where reading provides a natural way of testing and refreshing your knowledge of hundreds of characters. It is also a challenge to find a reading material attuned to your level if you are comfortable with fewer than a thousand characters. Mandarin Companion is great for 150-450 characters, and Jeff Pepper’s Journey to the West is great for 600+ characters. I am sure there will be other people talking about those two. This post, however, is about something completely different ™. Specifically, about making your own graded reader based on the number of characters you know, interests and a type of material to read. This is exactly what folks from yaya. press (https://www.yaya.press/) have come up with. They use an AI (ChatGPT) to write stories in any language, mimicking different writing styles, and based on your writing prompts. (Well, I tested only Chinese language.) You can import a number of words (characters) so that the stories will borrow heavily from your list. Not exclusively at the moment, but the creators do have plans to make them more focused on the provided input. The result is surprisingly fun. The famous/infamous AI hallucination is put here to good use. You can read the generated story, listen to it, use it for practicing your words, etc. BTW, the website is free to use for the time being.
It does seem like a fun way to get some new content ![]()
Your approach to it makes sense: use the hallucination to your advantage by having fun/memorable ways to see how words are used.
Would be curious on the error distribution and whether it’s improving. I’ve not been following along on the model evolution.
Still, theoretically, if the model trains enough on native content it should pick up and show you the same language patterns natives use.
This reminds me about the blog post duolingo put out on how they’ve been using AI.
For each lesson in the course sequence, Duolingo content developers write “raw” content that fits under the learning objective specified in the course plan, like talking about your hobbies. This includes everything from sentences, to paragraphs, to mini-dialogues that are common in day-to-day communication and illustrate the new words and concepts well. There’s also a need for some silliness to make learners laugh and help them stay engaged throughout their learning journey. Finally, we write translations for all the words and sentences so that learners can understand what they mean. But while human experts bring unique strengths to all these tasks, AI is a powerful partner! We build tools powered by AI algorithms to help content developers work faster and with fewer mistakes, focusing their brain power on what they do best. For example, we use AI to help create a range of possible translations of all the sentences so that we can later accept learners’ responses in cases when there are multiple correct ways of saying the same thing.
It looks like they still have dedicated content creators still. I’m curious if and or when they’ll switch over something more like yaya ![]()
Very interesting idea.
Tried out a few stories, even on the “newbie” setting, and it still spat out a lot of fancy expressions, like 閃爍薄霧 (“shimmering mist”) or 隱約 (“faintly visible”).
Might be that a model trained on thousands of heavy tomes of literary masterpieces has a different interpretation of “newbie” than us struggling humans.
However, if you prompt it like “[Topic], using mainly HSK1 words”, it helps a little, but it seems to quickly forget the initial prompt after a few lines, and you’re back at 疑惑和恐懼.
Agreed. The option of uploading a list of characters to study is there; supposedly, it would make the output exclusively use the upload. I tried with 50, 100, and 400 characters (copy-pasted from the HanziHero list) but still there were occasional extras here and there. I contacted the creators, and they said they were working on a solution.
This is a fairly new system (they opened in May), still a work in progress. If they successfully resolve this, it will be really useful. I enjoyed the craziness of stories ![]()
I am trying this out using NotebookLM.
NotebookLM is a free Google product that is very useful for studying, in general. The concept is AI, but trained only on the sources you provide.
I input some general instructions to Notebook LM about custom graded readers and my parameters before I input the vocabulary. Here is an example prompt: “Give me a short story (of a certain length) about a foreigner who goes to China and finds love.”
@phil A feature request for the Heroic team: regardless of platform, this will certainly be a thing going forward (custom graded readers). It would be super helpful if we could output our known words and characters, avoiding manual copy paste. For both words and characters, I filter by (All Levels) : 1) All, Skipped; 2) Learned, All.
Currently, you can actually get a CSV export of your words, characters, etc, by going to its curriculum page, and in the url, adding “.CSV” to the end of it, and you can save the page as a CSV.
You can do further filtering in Excel if you need to.
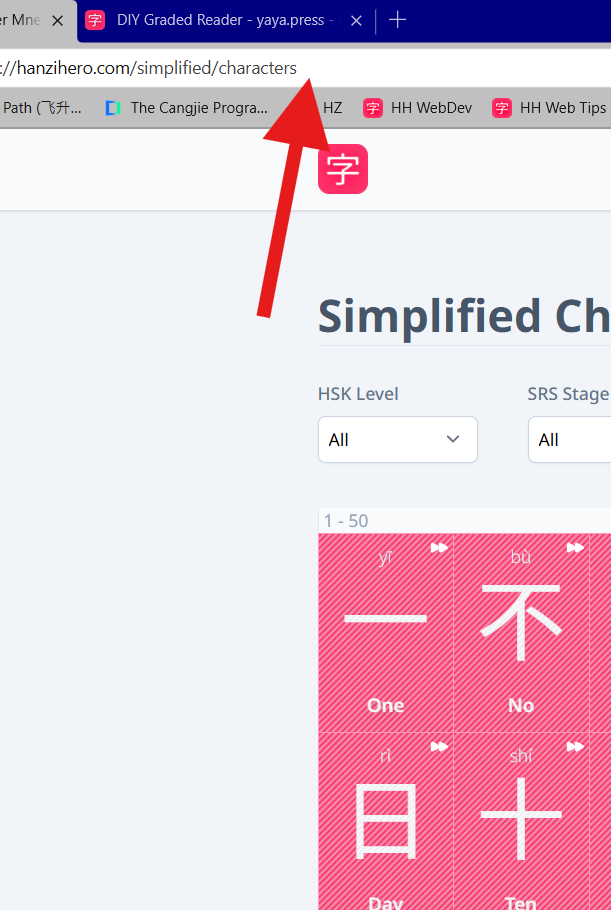
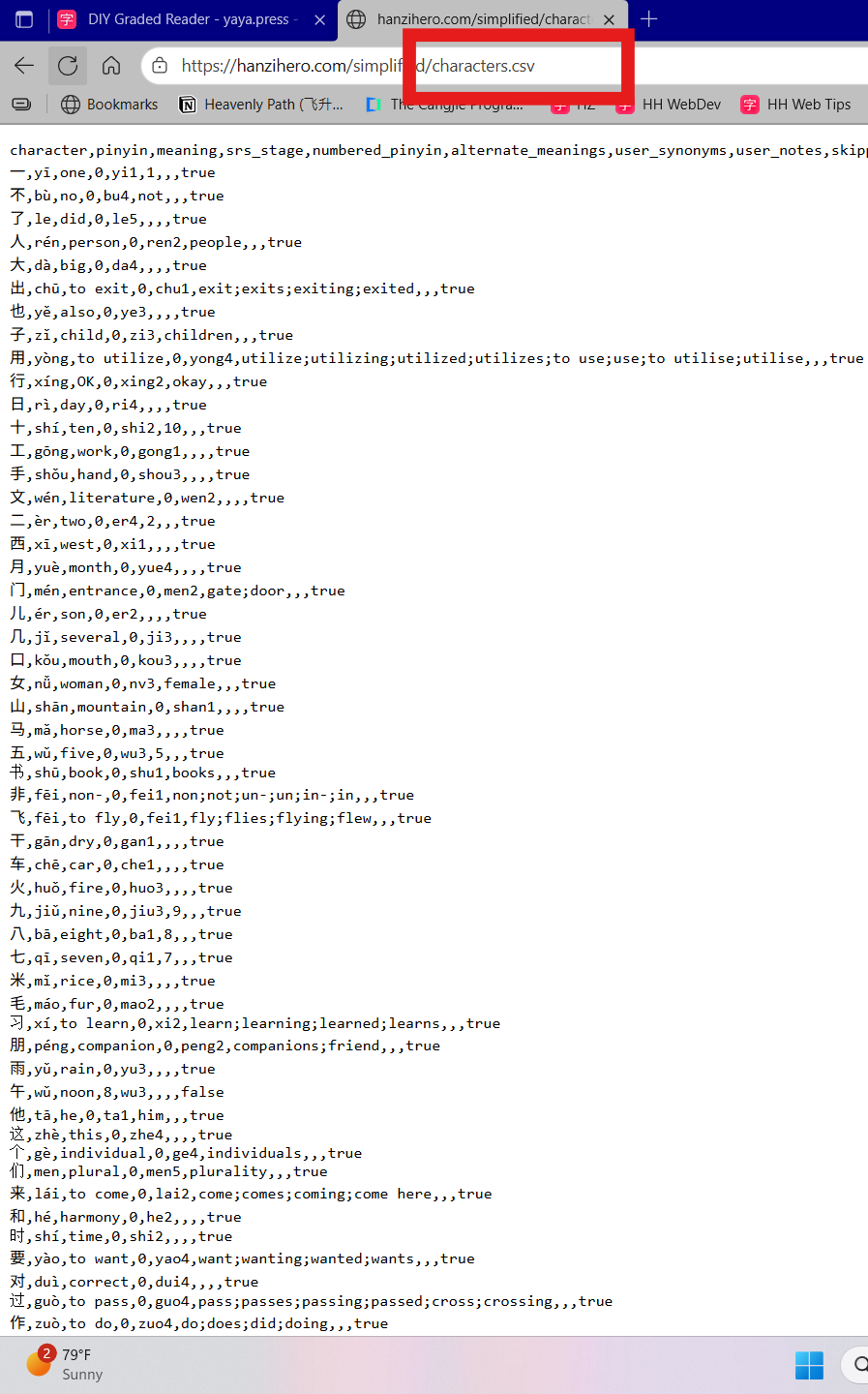
Cool hack, thank you! Works for the Words page, too. I had trouble getting the Hanzi to render in Excel, but the good thing is that the csv seems to automatically output my Learned and Skipped so I can just use it as is.
I was just wondering how to do this yesterday
Oh yeah I forgot in Excel it renders weirdly.
You can
- Open Excel (blank)
- Load Data in the data tab
- Before you finish loading the data, there will be a setting to adjust the encoding of the incoming file. I think most of the ones that say “Chinese” or “Mandarin” should be fine